
在股票量化分析、数据研究的过程中,完整下载全市场股票数据是一切分析的基础。
前两天,用baostock库下载数据时,由于使用了bs.query_stock_industry()函数,导致下载的股票数据仅包含A股的个别股票数据。经查阅资料发现,query_stock_industry()接口函数,仅针对性下载了A股主板市场的股票数据,完全忽略了深证、创业板(300开头)、科创板(688开头)的股票。
我现在就遇到了两个问题:
其一,如何下载全所有的股票名称和股票代码,这些代码应在之前我下载的各行业板块股票目录(csv文件)基础上,实现股票代码和股票名称的增补功能;
其二,如何保证在已下载的股票数据基础上,实现对欠缺的股票数据继续下载,减少不必要的时间浪费、减少频繁调用股票端口被封IP的风险。
我这次遇到的这个问题,我想很多和我一样的小伙伴都应该遇到过,中途中断后,实现“断点续传”功能,我这两天在家“闭门造车”就是要解决这个问题。

前后方案的对比情况
下面我结合我自己文件设置结构情况以及程序实现的部分细节情况,将解决思路做一简要陈述。
一、股票文件结构分析(一)结构说明
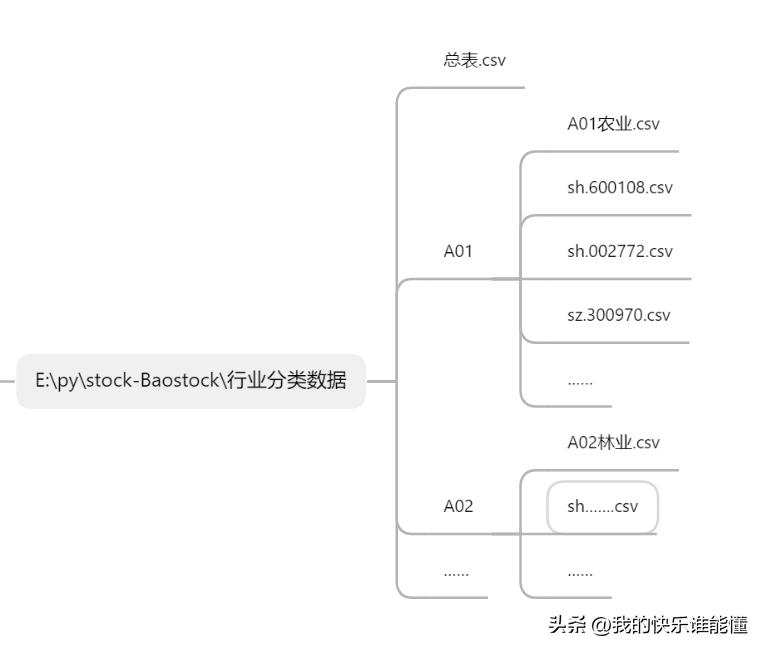
行业分类数据的存储结构示意图
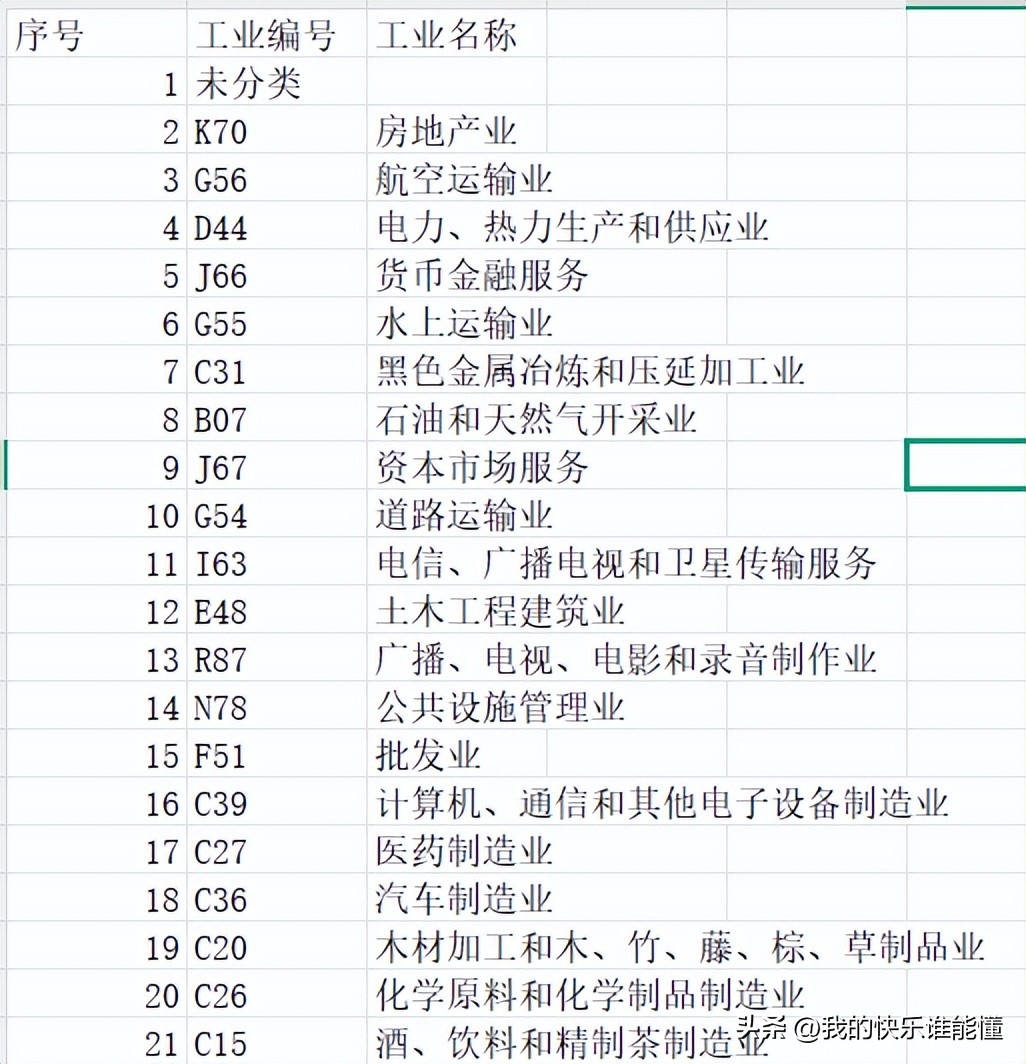
"总表.csv"文件 存储结构
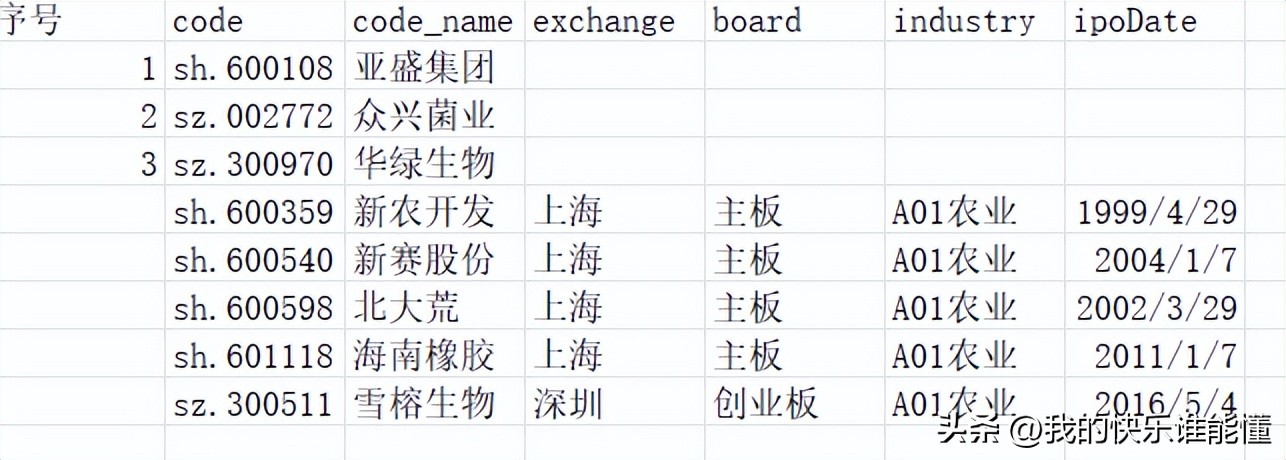
“A01农业.csv”文件 存储结构
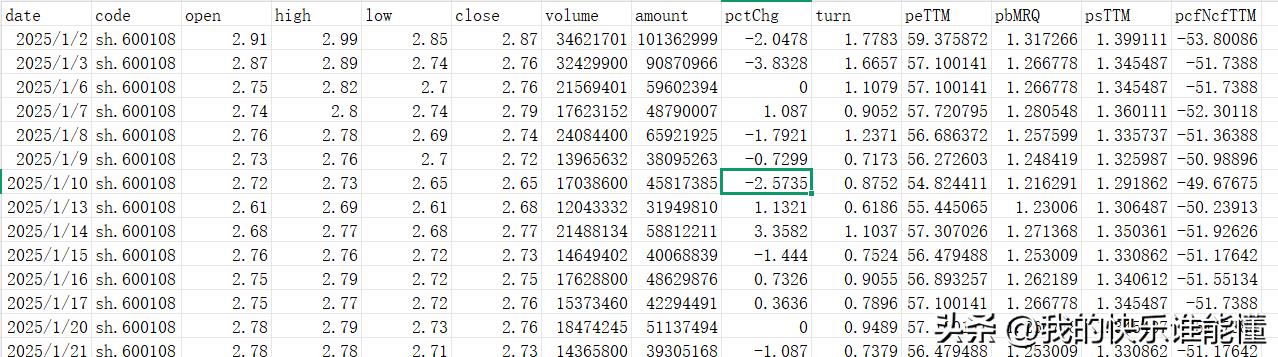
“sh.600108.csv”文件 存储结构
所有的行业分类数据均存储于“E:\py\stock-Baostock\行业分类数据”目录下,该目录下的文件存储有如下几个特征:
总表.csv文件存储着所有行业的信息,该文件中主要包括两列,一列“工业编号”,一列“工业名称”;基于“工业编号”创建目录,分别为A01、A02……做为子目录在子目录下,每个“工业编号”下存储着行业板块内所有股票基础信息,形成类似“A01农业.csv”、“A02林业.csv”的行业所有股票明细文件;另外该子目录下还保存着“工业编号”下所有的股票数据文件。行业所有股票明细文件中主要包括code和code_name两个字段,code指股票代码,code_name指股票名称。股票数据文件主要包括code、open、high等13个字段,这13个字段完整保存着一只股票所有信息。(二)存储结构特点
1、行业板块所有股票基础信息存储文件的前三个字母与子目录名一致,即“A01农业.csv”前三个字母A01是子目录的名字;
2、上证股票数据文件,一般带“sh.”;深证股票数据文件,一般带“sz.”;
3、总表.csv文件中的“工业编号”字段与子目录中的行业板块内所有股票基础信息文件名前三个字母相对应。
4、行业板块内所有股票基础信息文件中的“code”、“code_name”字段与股票数据文件中的“code”、“code_name”字段对应
(三)存储结构的优点
1、便于实现从板块→个股的研究思路,方便后期数据查找和数据分析工作
2、不便于查找不对应的个股信息数据,避免数据存储错位的情况发生,以及行业股票数据更新后,个股数据能对应下载。
3、关键字段的一一对应,确保数据不发生错误,便于手工核对信息,为开展大批量数据分析提供依据。
二、重构板块数据体系:筑牢断点续传的基础
要解决断点下载,首先要先把「全市场板块数据」理清楚——read_board.py重构了板块数据采集逻辑,不仅补齐了全板块数据,还实现了「数据更新比对」,为断点续传打下核心基础。
1. 全板块数据采集:覆盖主板/创业板/科创板
StockBoardManager类中的get_baostock_board_stocks方法,彻底解决了板块覆盖不全的问题:
Python
def get_baostock_board_stocks(self,target_boards=None, include_industry=True):
try:
# 获取全市场A股基本信息(不再局限于主板)
stock_rs = bs.query_stock_basic()
stock_df = stock_rs.get_data()
# 过滤已退市股票,保证数据有效性
if 'outDate' in stock_df.columns:
stock_df = stock_df
stock_df
'outDate'
.isna() | (stock_df
'outDate'
== '')
# 关键:给每只股票打板块标签(主板/创业板/科创板)
stock_df
'board'
= stock_df
'code'
.apply(self.get_stock_board)
stock_df
'exchange'
= stock_df
'code'
.apply(self.get_stock_exchange)
# 按目标板块筛选(支持主板/创业板/科创板同时筛选)
if target_boards is not None:
stock_df = stock_df
stock_df
'board'
.isin(target_boards)
# 补充行业分类,匹配原有数据体系
if include_industry:
industry_rs = bs.query_stock_industry()
industry_df = industry_rs.get_data()
industry_unique =
industry_df.drop_duplicates(subset=
'code'
, keep='first')
industry_dict = dict(zip(industry_unique
'code'
, industry_unique
'industry'
))
stock_df
'industry'
= stock_df
'code'
.apply(lambda x: industry_dict.get(x, "未知行业"))
return stock_df
except Exception as e:
print(f"获取股票数据时出错: {str(e)}")
return pd.DataFrame()
2. 断点续传核心:数据对比与更新
该文件通过「新采集的全板块数据 + 原有数据比对」的逻辑,实现了断点续传的核心基础:
例如,
save_stocks_by_board_and_industry方法会将全板块数据按板块/行业保存,同时生成汇总统计,方便后续与旧数据比对:
Python
def
save_stocks_by_board_and_industry(self, stock_df, output_dir="E:/py/stock-Baostock/行业分类数据/板块数据/"):
# 保存所有股票(新的全量数据)
all_stocks_path = os.path.join(output_dir, "all_stocks.csv")
stock_df.to_csv(all_stocks_path, index=False, encoding="utf-8-sig")
# 按板块拆分保存(方便后续对比旧数据)
if 'board' in stock_df.columns:
for board in stock_df
'board'
.unique():
board_df = stock_df
stock_df
'board'
== board
board_path = os.path.join(output_dir, f"{board}_stocks.csv")
board_df.to_csv(board_path, index=False, encoding="utf-8-sig")
# 生成汇总统计,便于校验数据完整性
summary_path = os.path.join(output_dir, "summary_statistics.txt")
with open(summary_path, 'w', encoding="utf-8") as f:
f.write("总股票数: {len(stock_df)}\n")
f.write("按板块统计:\n")
board_stats = stock_df
'board'
.value_counts()
for board, count in board_stats.items():
f.write(f" {board}: {count}只 ({count / len(stock_df) * 100:.2f}%)\n")
三、重构下载逻辑:dlAllStock_to_folder实现精准断点续传
如果说read_board.py解决了「该下哪些数据」的问题,那么read_stock.py则解决了「怎么断点续传下载」的问题——核心重构了dlAllStock_to_folder函数,并优化get_single_stock_data基础下载函数,实现了「只下缺失数据」的精准断点续传。
1. 基础保障:get_single_stock_data(稳定的单股票数据下载)
get_single_stock_data是数据下载的基础函数,负责单只股票的K线数据采集,为断点续传提供「原子化」的下载能力:
Python
def get_single_stock_data(stock_code, start_date = "2025-01-01", end_date = "2025-12-31"):
# 初始化Baostock连接
lg = bs.login()
# 定义全量字段(覆盖价格、成交量、估值指标)
fields = "date,code,open,high,low,close,volume,amount,pctChg,turn,peTTM,pbMRQ,psTTM,pcfNcfTTM"
# 调用接口获取历史K线数据
rs =
bs.query_history_k_data_plus(
code=stock_code,
fields=fields,
start_date=start_date,
end_date=end_date,
frequency="d",
adjustflag="3" # 不复权,保证数据原始性
# 解析数据并转换格式
data_list =
while (rs.error_code == '0') & rs.next():
data_list.append(rs.get_row_data())
bs.logout()
if data_list:
df = pd.DataFrame(data_list, columns=rs.fields)
# 数值字段类型转换(避免字符串导致的后续分析问题)
numeric_fields =
"open","high","low","close","volume","amount","pctChg","turn","peTTM","pbMRQ","psTTM","pcfNcfTTM"
for col in numeric_fields:
df = pd.to_numeric(df, errors='coerce')
print(f"成功获取 {stock_code} 数据,共 {len(df)} 条")
return df
else:
print(f"未获取到 {stock_code} 数据,错误信息:{rs.error_msg}")
return None
该函数的核心价值:
2. 断点续传核心:dlAllStock_to_folder(精准识别缺失数据)
重构后的dlAllStock_to_folder是断点续传的核心,通过「模糊查询→文件对比→内容比对」三层逻辑,精准识别缺失数据并仅下载未采集的部分:
Python
def dlAllStock_to_folder(folder_path):
"""从baostock读取所有股票到本地文件夹,实现断点续传"""
if not os.path.exists(folder_path):
print(f"错误:文件夹 '{folder_path}' 不存在!")
return None
# 遍历行业目录(按板块/行业分类的文件夹)
for folder in os.listdir(folder_path):
if folder.endswith(".csv"):
continue
folder_son = os.path.join(folder_path, folder)
# 步骤1:模糊查询行业总目录文件(如“J66房地产业.csv”)
match_file = folder + "*.csv"
file_paths = glob.glob(os.path.join(folder_son, match_file))
if not file_paths:
continue
# 步骤2:遍历目录内文件,排除行业总目录,筛选已下载的股票文件
l =
for file in os.listdir(folder_son):
file_name = os.path.basename(file)
# 排除行业总目录文件,只保留已下载的股票数据文件
Contentfiles =
os.path.basename(path) for path in file_paths
if file_name not in Contentfiles:
# 步骤3:文件名与行业总目录内容比对,判断是否缺失
code = os.path.splitext(file) # 提取股票代码(如sh.600015)
# 仅下载未在本地的股票数据(断点续传核心)
df = get_single_stock_data(code)
if df is not None:
df.to_csv(f"{folder_son}/{code}.csv", index=False, encoding="utf-8-sig")
# 接口频率控制,避免被限制
time.sleep(random.uniform(2, 5))
关键逻辑拆解:
四、股票数据断点续传的实操注意事项
从上述实现过程来看,股票数据的断点续传并非简单的「重新下载」,而是需要兼顾数据完整性、接口稳定性、文件规范性,核心注意事项有5点:
1. 统一文件编码格式
股票数据文件涉及中文(如行业名称),需统一使用utf-8-sig或gbk编码,避免读取时出现乱码,导致比对失败。例如代码中明确指定:
Python
df.to_csv(f"{folder_son}/{code}.csv", index=False, encoding="utf-8-sig")
2. 严格控制接口调用频率
Baostock等免费数据接口有调用频率限制,需通过time.sleep(random.uniform(2, 5))随机延时,避免因高频调用被封禁,导致断点续传中途中断。
3. 规范目录与文件命名4. 数据格式校验不可少
下载后的数值型字段(如开盘价、成交量)需转换为float类型,避免字符串格式导致后续比对、分析时出现错误,这也是get_single_stock_data中重点处理的环节。
5. 保留汇总统计文件
通过summary_statistics.txt等汇总文件记录各板块/行业的股票数量,每次续传后校验数量是否匹配,及时发现「漏下/下载失败」的股票。
总结
股票数据的断点下载问题,本质是「数据范围不全」+「下载逻辑无校验」导致的。通过重构板块数据体系(
read_board.py
(read_board.py))明确「该下哪些数据」,再通过优化下载逻辑(
read_stock.py
(read_stock.py))实现「只下缺失数据」,最终形成了覆盖全市场、支持断点续传的完整采集方案。
这套思路不仅适用于股票数据下载,也可迁移到金融、电商等领域的大批量数据采集场景——核心是「先明确完整清单,再通过比对实现精准续传」,既提升效率,又保障数据完整性。
还没有评论,来说两句吧...